


引言
首先观察网站结构

每张图片右上角都有保存的功能,检查源码发现这个保存是一个url
即
那不就简单了,随便使用python模拟访问一下
import requests
response = requests.get('https://api.zzzmh.cn/v2/bz/v3/getUrl/286484bdc06b47dab2f5cdb9a3ca86e229')
print(response.text)
# 确保响应的内容是二进制数据
if response.status_code == 200:
with open(f'{i}.jpg', 'wb') as file:
file.write(response.content)
print("图片已成功保存。")
else:
print(f"请求失败,状态码: {response.status_code}")图片被成功的下载了下来,而且还不需要验证直接get就可以得到。
现在就是观察这个 url 的时候了,这儿列举几个
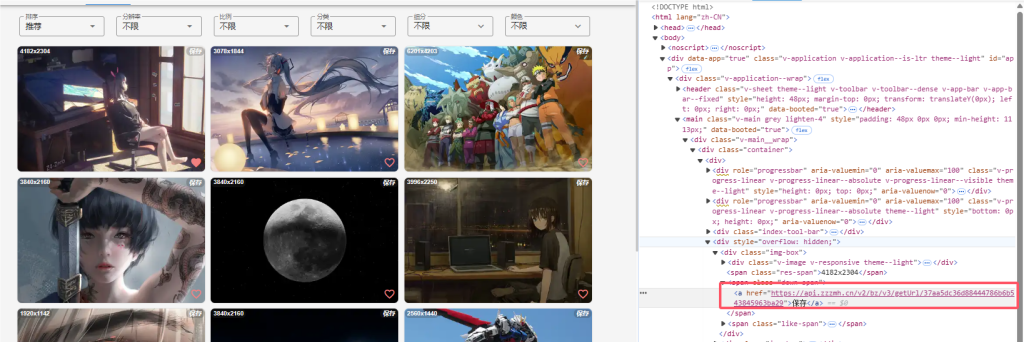
https://api.zzzmh.cn/v2/bz/v3/getUrl/37aa5dc36d88444786b6b543845963ba29
https://api.zzzmh.cn/v2/bz/v3/getUrl/1b87e2c5880511ebb6edd017c2d2eca229
https://api.zzzmh.cn/v2/bz/v3/getUrl/ba3dee63249d43e88b3d5c5e7c75ef2329现在就是小学生的作业了,找规律
https://api.zzzmh.cn/v2/bz/v3/getUrl/这个是一个相同点前缀。
只有后面的东西不同,还有一个就是最后都有一个29
所以前面的部分例如37aa5dc36d88444786b6b543845963ba
这个好像是服务器给每一张图片生成的,不知道是不是随机的,写法咋们也看不到,所以暂时先不管,我想这个网站作者也是一个大佬,首页图片的数据应该不是直接写入到页面中的,这个网站是vue与html等等构成的。
遇事不决便刷新观察,同时为了观察清楚,将页面缓存禁用,同时限制加载速度

点击刷新观察

他优先出来的是 ui 这说明这个过程加载了一个josn数据用来构建主体支撑
思路明确找加载的数据,在网络中查看,勾选XHR,剔除掉媒体文件
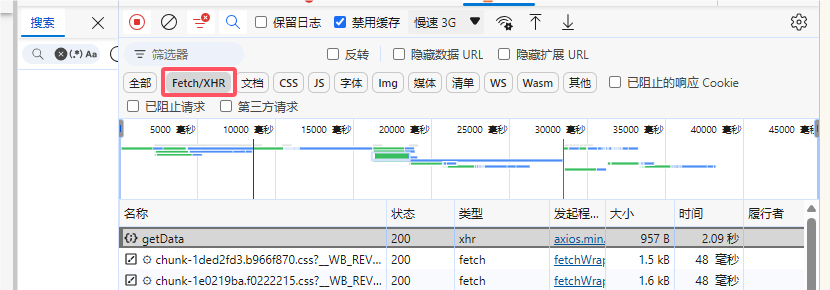
第一个就是标准的数据传输文件,data这个类文件最为常用
点开查看响应数据是否加密,很明显直接明文传输

其中【i】值不就是我们在连接中找到的不同的地方吗。所以差不多了开始写代码
上代码
先理清思路,批量获取【i】值,构建链接批量下载
首先写一个获取【i】值的代码,继续观察这个getData数据传输的过程,看看负载
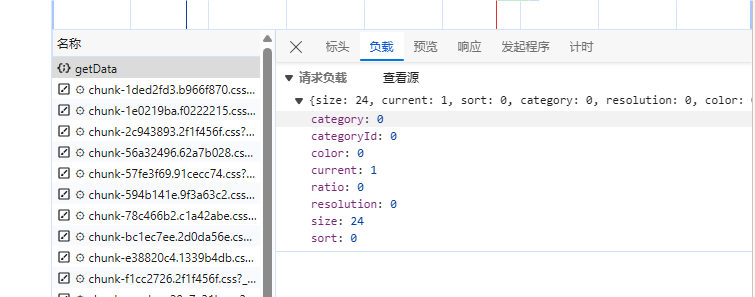
不难看出current为页码,size为加载数据的多少。翻到最下面,共计1733页

现在就是将这个getdata模拟到python上,这个访问请求到新建标签页时候会显示网络错误,500
所以这儿给你们推荐一个网站【Convert curl commands to code (curlconverter.com)】用来将curl处理为各种语言的请求。
右键这个请求,复制,复制curl(bash)
粘贴到处理curl的网站,粘贴到红色的框中
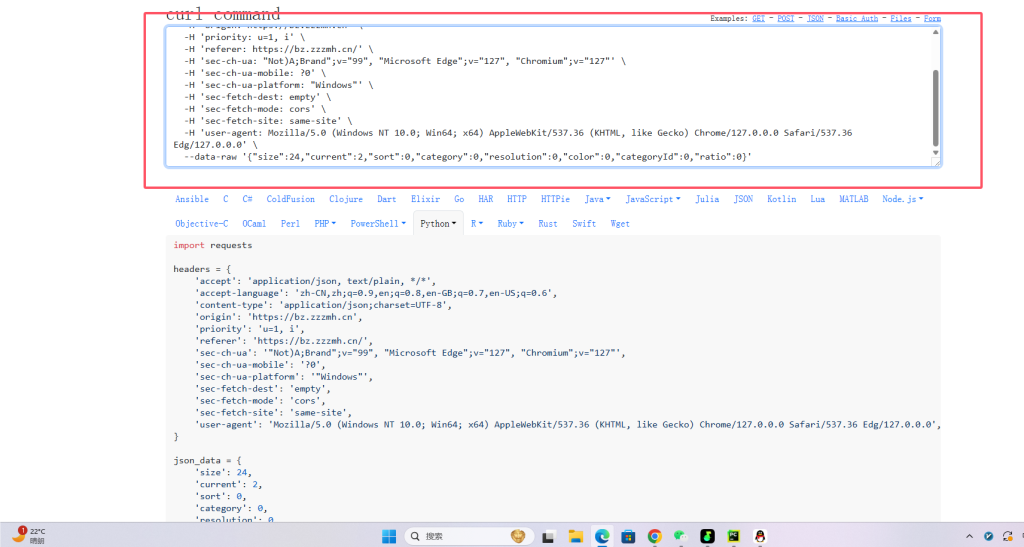
下面会自动显示python的模拟请求
import requests
headers = {
'accept': 'application/json, text/plain, */*',
'accept-language': 'zh-CN,zh;q=0.9,en;q=0.8,en-GB;q=0.7,en-US;q=0.6',
'content-type': 'application/json;charset=UTF-8',
'origin': 'https://bz.zzzmh.cn',
'priority': 'u=1, i',
'referer': 'https://bz.zzzmh.cn/',
'sec-ch-ua': '"Not)A;Brand";v="99", "Microsoft Edge";v="127", "Chromium";v="127"',
'sec-ch-ua-mobile': '?0',
'sec-ch-ua-platform': '"Windows"',
'sec-fetch-dest': 'empty',
'sec-fetch-mode': 'cors',
'sec-fetch-site': 'same-site',
'user-agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/127.0.0.0 Safari/537.36 Edg/127.0.0.0',
}
json_data = {
'size': 24,
'current': 2,
'sort': 0,
'category': 0,
'resolution': 0,
'color': 0,
'categoryId': 0,
'ratio': 0,
}
response = requests.post('https://api.zzzmh.cn/v2/bz/v3/getData', headers=headers, json=json_data)
# Note: json_data will not be serialized by requests
# exactly as it was in the original request.
#data = '{"size":24,"current":2,"sort":0,"category":0,"resolution":0,"color":0,"categoryId":0,"ratio":0}'
#response = requests.post('https://api.zzzmh.cn/v2/bz/v3/getData', headers=headers, data=data)我们现在需要获取全部的数据,就需要写循环处理
import requests
headers = {
'accept': 'application/json, text/plain, */*',
'accept-language': 'zh-CN,zh;q=0.9,en;q=0.8,en-GB;q=0.7,en-US;q=0.6',
'cache-control': 'no-cache',
'content-type': 'application/json;charset=UTF-8',
'origin': 'https://bz.zzzmh.cn',
'pragma': 'no-cache',
'priority': 'u=1, i',
'referer': 'https://bz.zzzmh.cn/',
'sec-ch-ua': '"Not)A;Brand";v="99", "Microsoft Edge";v="127", "Chromium";v="127"',
'sec-ch-ua-mobile': '?0',
'sec-ch-ua-platform': '"Windows"',
'sec-fetch-dest': 'empty',
'sec-fetch-mode': 'cors',
'sec-fetch-site': 'same-site',
'user-agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/127.0.0.0 Safari/537.36 Edg/127.0.0.0',
}
# 创建或输出文件
with open('output.txt', 'w', encoding='utf-8') as file:
file.write("") # 清空文件内容
for current_page in range(1, 1735): # 从第 1 页到第 1734 页
json_data = {
'size': 24,
'current': current_page,
'sort': 0,
'category': 0,
'resolution': 0,
'color': 0,
'categoryId': 0,
'ratio': 0,
}
response = requests.post('https://api.zzzmh.cn/v2/bz/v3/getData', headers=headers, json=json_data)
# 确保响应的内容是 JSON 数据
if response.status_code == 200:
response_json = response.json()
# 检查响应中是否包含 "data" 和 "list"
if 'data' in response_json and 'list' in response_json['data']:
items = response_json['data']['list']
i_values = [item['i'] for item in items]
# 将 'i' 值追加到 txt 文件中
with open('output.txt', 'a', encoding='utf-8') as file:
for value in i_values:
#一行一个数据
file.write(f"{value}\n")
print(f"第 {current_page} 页的数据已写入 'output.txt' 文件中。")
else:
print(f"第 {current_page} 页的响应中没有 'data' 或 'list'。")
else:
print(f"第 {current_page} 页请求失败,状态码: {response.status_code}")
print("所有页的数据已写入 'output.txt' 文件中。")好了现在所有的【i】值都写入到txt文件中了
紧接着就可以下载图片了
import requests
import os
# 确保图片保存目录存在
image_folder = 'image'
os.makedirs(image_folder, exist_ok=True)
# 读取 'output.txt' 文件中的所有 'i' 值
with open('output.txt', 'r', encoding='utf-8') as file:
i_values = file.readlines()
for i in i_values:
i = i.strip() # 去除可能存在的空白字符
if i:
url = f'https://api.zzzmh.cn/v2/bz/v3/getUrl/{i}29'
response = requests.get(url)
# 确保响应的内容是二进制数据
if response.status_code == 200:
file_path = os.path.join(image_folder, f'{i}.jpg')
with open(file_path, 'wb') as file:
file.write(response.content)
print(f"图片 {i}.jpg 已成功保存。")
else:
print(f"请求失败,状态码: {response.status_code},图片 {i}.jpg 未能保存。")这个代码在运行的时候
发现有个别的会出现状态码错误,一般和url有关系,再次看了网页下载结构发现有的后缀为【29】有的为【19】而且所有的图片并不是jpg结尾的
所以这里使用相应内容中【Content-Type】来确定图片的后缀
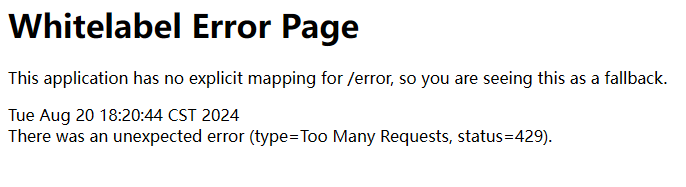
所以再增加两个 if 来解决这两个问题,以及在测试过程中出现了这个东西,所以再增加一个time限制,以避免被封ip。
import requests
import os
import time
# 确保图片保存目录存在
image_folder = 'image'
os.makedirs(image_folder, exist_ok=True)
# 读取 'output.txt' 文件中的所有 'i' 值
with open('output.txt', 'r', encoding='utf-8') as file:
i_values = file.readlines()
for i in i_values:
i = i.strip() # 去除可能存在的空白字符
if i:
# 尝试第一个 URL
url = f'https://api.zzzmh.cn/v2/bz/v3/getUrl/{i}29'
response = requests.get(url)
# 如果请求状态是 403,则尝试使用备用 URL
if response.status_code == 403:
url = f'https://api.zzzmh.cn/v2/bz/v3/getUrl/{i}19'
response = requests.get(url)
# 确保响应的内容是二进制数据
if response.status_code == 200:
# 获取内容类型以确定图片格式
content_type = response.headers.get('Content-Type', '')
if 'image/jpeg' in content_type:
extension = 'jpg'
elif 'image/png' in content_type:
extension = 'png'
elif 'image/webp' in content_type:
extension = 'webp'
else:
extension = 'bin' # 如果无法确定格式,使用通用扩展名
file_path = os.path.join(image_folder, f'{i}.{extension}')
with open(file_path, 'wb') as file:
file.write(response.content)
print(f"图片 {i}.{extension} 已成功保存。")
else:
print(f"请求失败,状态码: {response.status_code},图片 {i} 未能保存。")
# 每处理一行等待 2 秒
print(f"等待 5 秒...")
time.sleep(5)其实有细心的小伙伴应该发现了,在getdata文件中【t】值就是处理这个问题的关键。但是这个她只有两个不同的值,所以就不需要再写入一个excel来判定是否用哪个url了,直接在源码中 if 这样应该快点。
所上最终代码








![表情[haobang]-WordPress主题模板-zibll子比主题](https://www.zibll.com/wp-content/themes/zibll/img/smilies/haobang.gif)




