



观察
爬虫嘛,不可能说直接上手就写,本人目前没有那个境界。我在浏览器搜了一大堆,好像没有突破原图不限量下载的这个技术方案,我的这个只能说钻了网站的漏洞。
上图:

他这个网站不是前后端分离的,数据加载直接在html中显示没有任何的json数据传输,所以直接观察源代码
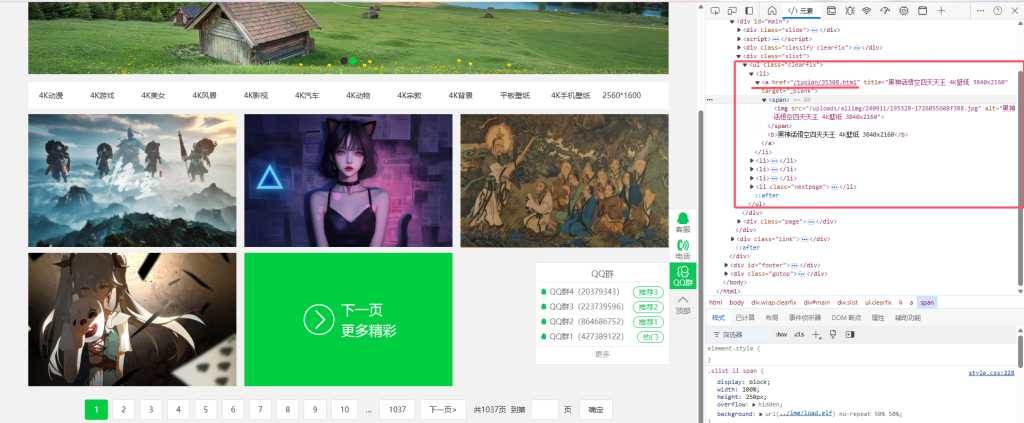
如图所示每一张图片都有一个详情链接,类似于wp的文章类型,这就好解决了
点开一张图片查看里面到底是个什么情况呗
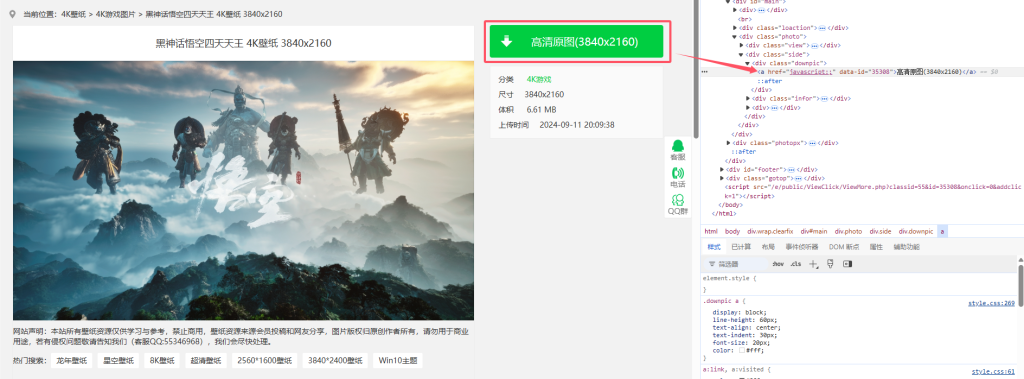
下载原图的请求链接为【javascript】点击模式
思路
现在有一个大概的思路了,爬取每一张图片的详情页链接,再用f12抓包下载过程中产生的请求链接嘛,在python中模拟,所以上手
开干
先抓包,看他请求过程中需要的参数是什么
抓包得到
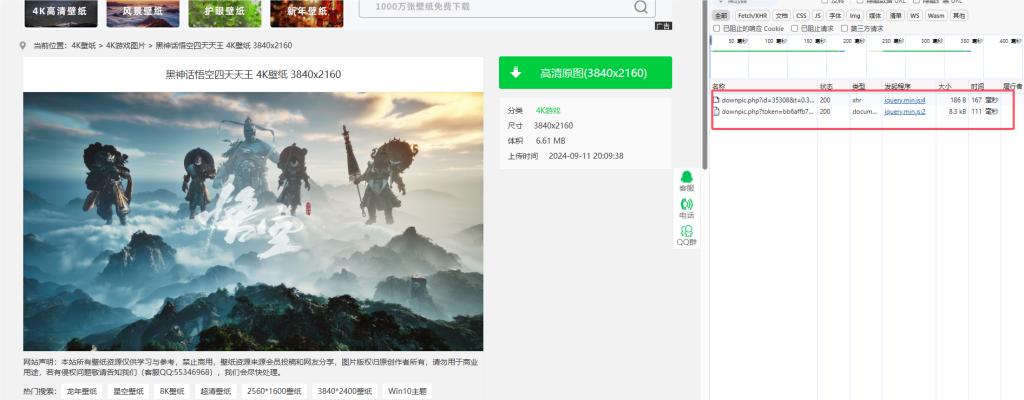
好了有两个过程一个一个来看
第一个的负载情况为

这个id我们观察整个详情页链接就会发现和后缀一样的,
https://pic.netbian.com/tupian/35308.html
但是这个【t】值是个啥?。看不懂的先放着,不用管
看返回数据

返回值中有一个可用值【pic】
里面有个链接是携带参数【token】的
好嘛,看第二个请求链接

第二个的请求负载就是这个token,而且后面也没有请求了,现在就明了了,第一个请求向服务器索取一个验证值【token】第二个请求链接才应该是下载文件的请求。
在这给你们推一个网站,我之前有说过的。处理curl的
https://curlconverter.com/
首先右键复制为curl【bash】
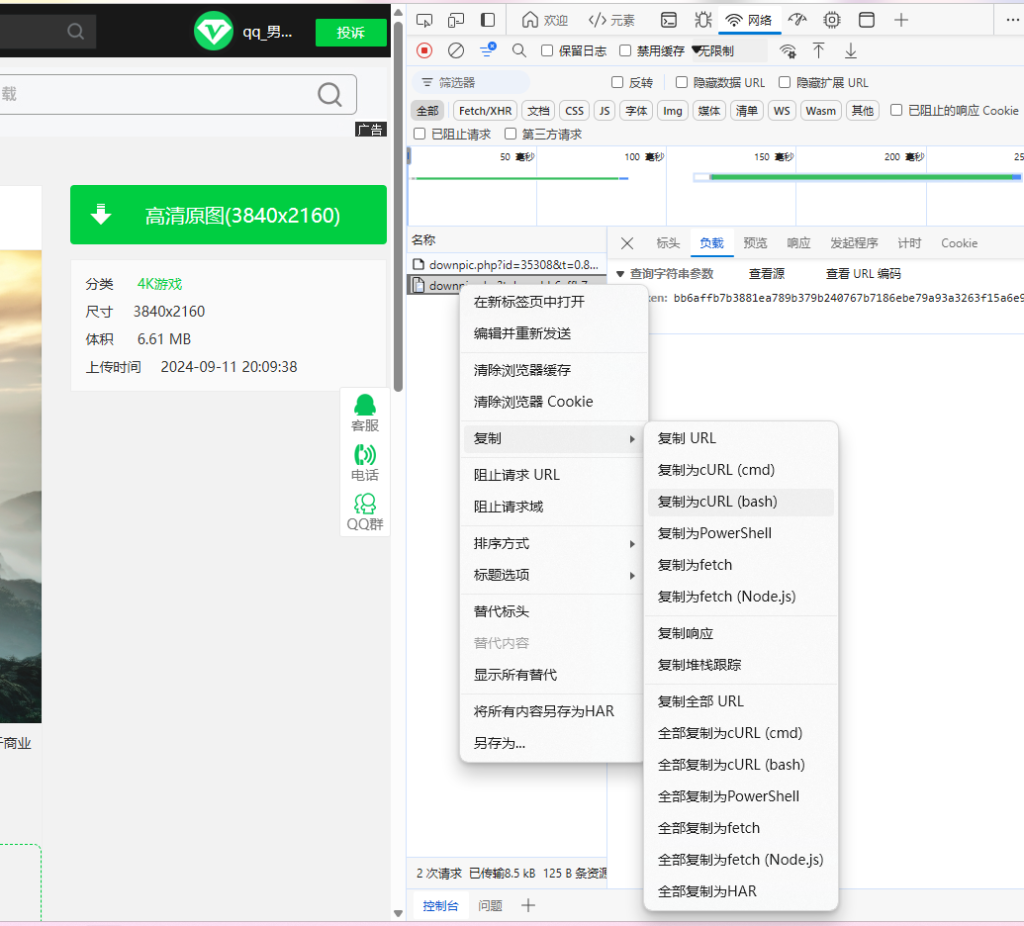
将复制的值粘贴到网站https://curlconverter.com/中,如下图所示
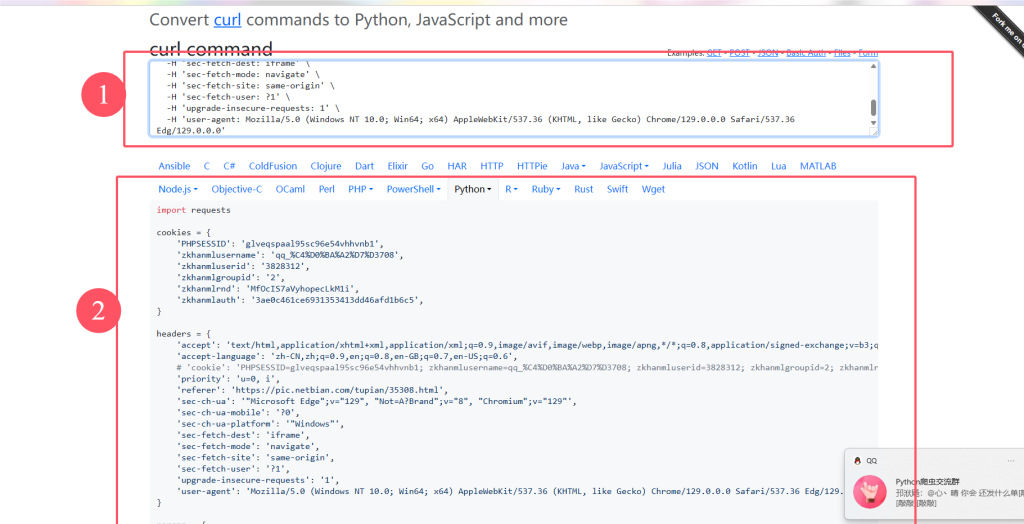
复制到1,python模拟请求代码会出现在下方。好吧,我们现在看看返回数据是什么

在这可以看出来返回的数据为一堆乱码,但是熟悉的朋友知道,这个像二进制文件数据,显示乱码了而已
直接尝试保存嘛
保存模块为
with open('downloaded_image.jpg', 'wb') as file:
file.write(response.content)运行输出
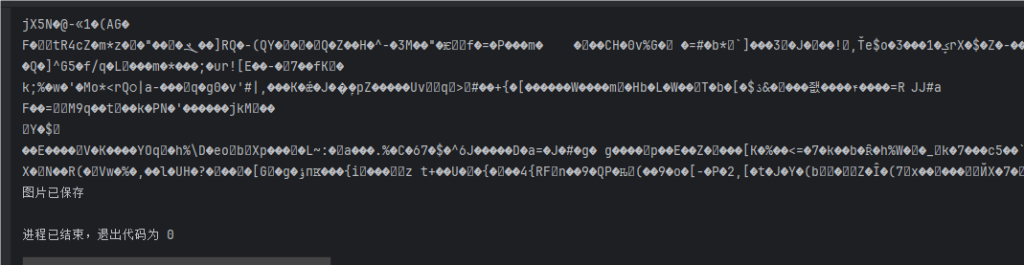
看起来是正常的
看下载文件是否正常
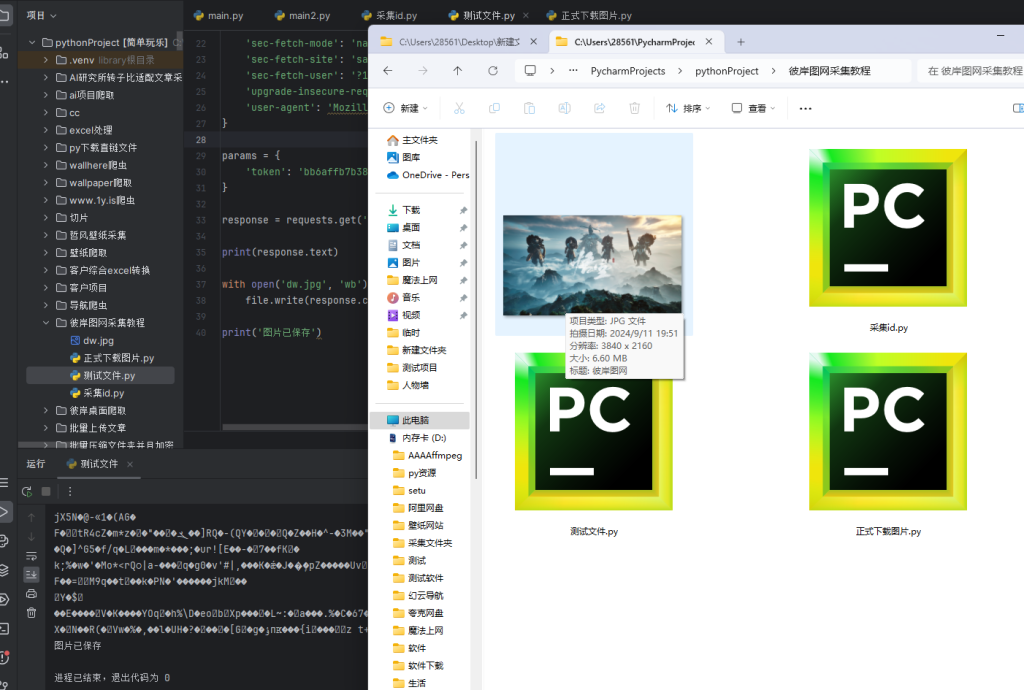
ok现在解决了,说明可以通过爬虫下载,但是我们都知道普通用户一天最多一张图,一元赞助最多10张,月费会员最多100张,但是呢他的网站有个漏洞,可以无限制下载。好了剩下的内容就需要购买了。我在搜索引擎中没有发现关于批量下载原图的。所以呢。收个费。有可能我是第一个应该有大佬做出来了的。但是我没找到这方面的资料。
好了看看我的成果吧

20861张图片共计61GB,绝对原图

好了上代码,付费获取哦
对了如果需要所有图片的话找我购买:99.不讲价,不是百度网盘,有高速链接的


 呦西 现在电脑下载不了了
呦西 现在电脑下载不了了

![表情[chi]-WordPress主题模板-zibll子比主题](https://www.zibll.com/wp-content/themes/zibll/img/smilies/chi.gif)


